Installation¶
Nordlys is a general-purpose semantic search toolkit, which can be used either as a Python package, as a command line tool, or as a service.
Data are a first-class citizen in Nordlys. To make use of the full functionality, the required data backend (MongoDB and Elasticsearch) need to be set up and data collections need to be loaded into them. There is built-in support for specific data collections, including DBpedia and Freebase. You may use the data dumps we prepared, or download, process and index these datasets from the raw sources.
1 Installing the Nordlys package¶
This step is required for all usages of Nordlys (i.e., either as a Python package, command line tool or service).
1.1 Environment¶
Nordlys requires Python 3.5+ and a Python environment you can install packages in. We highly recommend using an Anaconda Python distribution.
1.2 Obtain source code¶
You can clone the Nordlys repo using the following:
$ git clone https://github.com/iai-group/nordlys.git
1.3 Install prerequisites¶
Install Nordlys prerequisites using pip:
$ pip install -r requirements.txt
If you don’t have pip yet, install it using
$ easy_install pip
Note
On Ubuntu, you might need to install lxml using a package manager
$ apt-get install python-lxml
1.4 Test installation¶
You may check if your installation has been successful by running any of the cmd_usage, e.g., from the root of your Nordlys folder issue
$ python -m nordlys.core.retrieval.retrieval
Alternatively, you can try importing Nordlys into a Python project. Make sure your local Nordlys copy is on the PYTHONPATH. Then, you may try, e.g., from nordlys.core.retrieval.scorer import Scorer.
Mind that this step is only to check the Python dependencies. It is rather limited what you can do with Nordlys without setting up data backed and loading the data components.
2 Setting up data backend¶
We use MongoDB and Elasticsearch for storing and indexing data. You can either connect to these services already running on some server or set these up on your local machine.
2.1 MongoDB¶
If you need to install MongoDB yourself, follow the instructions here.
Adjust the settings in config/mongo.json, if needed.
If you’re using macOS, you’ll likely need to change the soft limit of maxfiles to at least 64000, for mongoDB to work properly. Check the maxfiles limit of your system using:
$ launchctl limit
2.2 Elasticsearch¶
If you need to install Elasticsearch yourself, follow the instructions here. Note that Elasticsearch requires Java version 8.
Adjust the settings in config/elastic.json, if needed.
Nordlys has been tested with Elasticsearch version 5.x (and would likely need updating for newer version).
3 Loading data components¶
Data are a crucial component of Nordlys. While most of the functionality is agnostic of the underlying knowledge base, there is built-in support for working with specific data sources. This primarily means DBpedia, with associated resources from Freebase.
Specifically, Nordlys is shipped with functionality designed around DBpedia 2015-10, and the dumps we provide are for that particular version. However, we provide config files and instructions for working with DBpedia 2016-10, should you prefer a newer version.
Note that you may need only a certain subset of the data, depending on the required functionality. See Data components for a detailed description.
The figure below shows an overview of data sources and their dependencies.
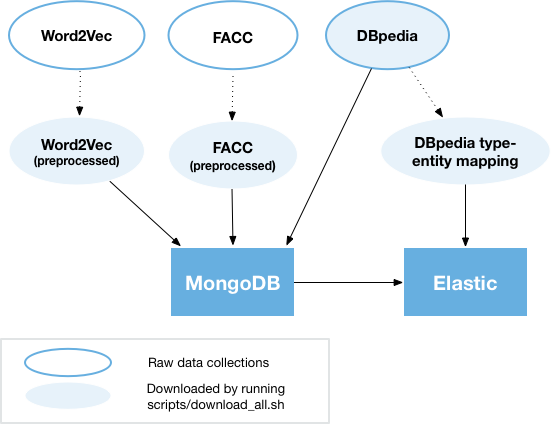
3.1 Load data to MongoDB¶
You can either load the data to MongoDB (i) from dumps that we made available or (ii) from the raw source files (DBpedia, FACC, Word2vec, etc.). Below, we discuss the former option. For the latter, see Building MongoDB sources from raw data. Note that processing from the raw sources takes significantly longer because of the nontrivial amount of data.
To load the data to MongoDB, you need to run the following commands from the main Nordlys folder. Note that the first dump is required for the core Nordlys functionality over DBpedia. The other dumps are optional, depending on whether the respective functionality is needed.
| Command | Required for |
|---|---|
./scripts/load_mongo_dumps.sh mongo_dbpedia-2015-10.tar.bz2 |
All |
|
EL and EC |
./scripts/load_mongo_dumps.sh mongo_word2vec-googlenews.tar.bz2 |
TTI |
3.2 Download auxiliary data files¶
The following files are needed for various services. You may download them all using
$ ./scripts/download_auxiliary.sh
| Description | Location (relative to main Nordlys folder) | Required for |
|---|---|---|
| Type-to-entity mapping | data/raw-data/dbpedia-2015-10/type2entity-mapping |
TTI |
| Freebase-to-DBpedia mapping | data/raw-data/dbpedia-2015-10/freebase2dbpedia |
EL |
| Entity snapshot | data/el |
EL 1 |
- 1 If entity annotations are to be limited to a specific set; this file contains the proper named entities in DBpedia 2015-10
3.3 Build Elastic indices¶
There are multiple elastic_indices created for supporting different services. Run the following commands from the main Nordlys folder to build the indices for the respective functionality.
| Command | Source | Required for |
|---|---|---|
./scripts/build_dbpedia_index.sh core |
MongoDB | ER, EL, TTI |
./scripts/build_dbpedia_index.sh types |
Raw DBpedia files 1 | TTI |
./scripts/build_dbpedia_index.sh uri |
MongoDB | ER 2 |
- 1 Requires short entity abstracts and instance types files
- 2 only for ELR model
Note
To use the 2016-10 version of DBpedia, add 2016-10 as a 2nd argument to the above scripts.